I earlier described the differences between ontologies and taxonomies and their importance when it comes to organizing the things we know, or would like to know. Now comes an interesting question (the first of several) - once you have settled on an area of interest, sailing ships and sealing wax for example, how will you learn the connections between the documents and sources that you are likely to run across? I imagine most of us have experienced this type of problem at one time or another - let's say you'd like to know more about bronze statues. You mention this to a friend and almost before you stop speaking you've been handed a thundering fat textbook on "metallurgy through the ages". Like, Oh! Joy, actually I was looking for something with a little more art.
On its face there is no good way to know if this is a great first step or a rat trap of confusion. Ideally what you'd really like to know is: how does this particular text stack-up against similar texts in roughly the same area and, perhaps, how well is the author known and revered by others with similar interests to you own.
Librarians have fortunately crafted a solution to this type of problem - it's called a citation index. It works quite well for scientific journals. Basically, someone goes to a LOT of trouble to methodically count how often an article in a scientific journal has been referenced by other authors. You can usually also find a raw list of publications by an authors name. Taken together this information can be used to select what seems to be the most useful/insightful articles from a stack of similar-looking papers. In fact, these scores have often been pretty good predictors of who will win Nobel prizes.
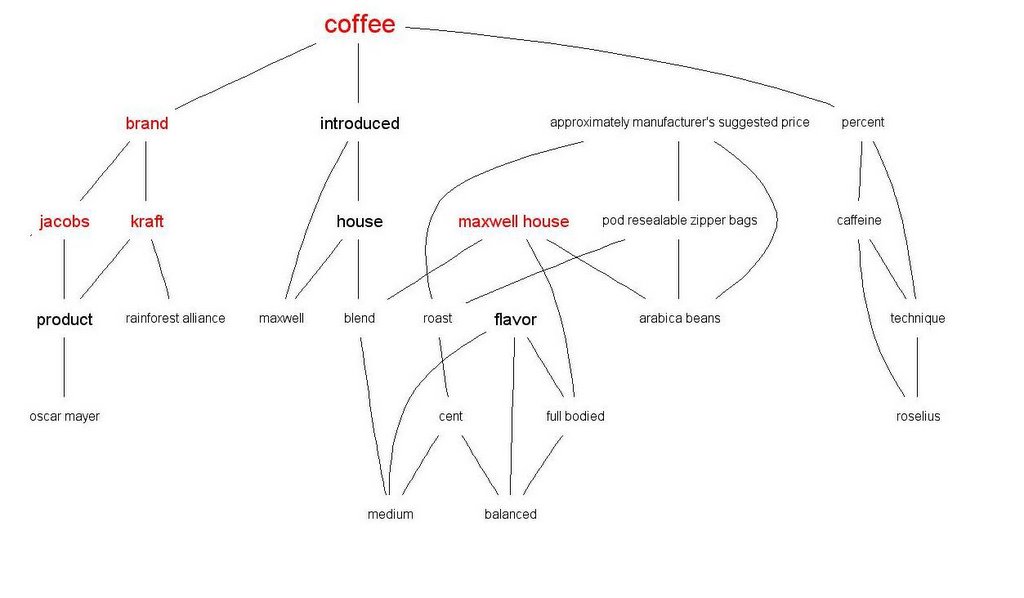
Unfortunately an index of this type is usually not available when one is presented with documents from the non-scientific world - take websites for example. Without any prior knowledge of the contents of a site is there any way to get a grip on potentially useful relationships between documents stored there? And, can these relationships be presented on-the-fly? With the great power of computers and modern semantics the answer if a resounding YES.
The graphic above shows the relationships between the key concepts related to "coffee" presented on the Kraft website. The engine has clearly identified a relationship between "coffee" and "roselius" - like what-da-f is roselius; Dr. Roselius invented the modern decaffeinating process.
Don't try this on Google where keyword search can't tell the difference between "articles by George Bush" and "articles about George Bush" ... just because they are rich doesn't mean they aren't low class!

No comments:
Post a Comment